2023. 4. 26. 17:27ㆍAI • 빅데이터 인사이트
AI, 이것만 알면 됩니다 ⑤ - 한국어 GPT
무서운 속도로 발전해가는 AI를 이해하기 위해 필요한 지식을 쉽게 풀어 썼습니다.
챗GPT로 인해 본격적으로 시작된 AI 시대, 이것만은 꼭 알아가세요!
목차
만만치 않은 한국어 GPT
한국어 GPT가 마주한 과제
만만치 않은 한국어 GPT
국내 기업은 한국어 특화 AI 모델에 주력 중입니다.
Open AI에서 제공하는 GPT-4 모델의 한국어 성능(77.0%)이 영어 성능(85.5%)보다 떨어지기 때문에 ‘한국어 특화’를 돌파구로 삼고 있는 모습으로 보입니다.
하지만 한국어 특화 AI 모델이 그리 쉬워 보이진 않습니다.
‘한국어’라는 특수성에 기인한 한국어 GPT가 어려운 세 가지 이유를 알아보겠습니다.
첫 번째 이유: 절대적으로 적은 양질의 학습 데이터
대규모 언어 모델(LLM)은 기사, 소설, 에세이, 웹사이트, 전자 문서 등 다양하고 방대한 자료를 학습 데이터로 필요로 합니다.
번외로 웹 상의 자료를 무분별하게 긁어 모았다는 의혹을 받는 챗GPT는 현재 저작권 무단 침해 이슈에 휘말리고 있습니다.
LLM에서 학습데이터는 매우 중요합니다.
하지만 한국어 텍스트 자료는 품질과 다양성 측면에서 영어에 비해 절대적으로 부족하며, 양적으로도 마찬가지입니다.
두 번째 이유: 토큰화의 불리함
<AI, 이것만 ④>에서 ‘토큰’에 대해서 잠깐 언급했었습니다.
입력 혹은 출력하는데 사용되는 텍스트 데이터 내 ‘의미를 가진 최소 말의 단위(형태소)’가 토큰이며, 이를 기준으로 LLM이 작동한다고 볼 수 있습니다.
컴퓨터는 사람의 말(자연어)을 그대로 이해할 수 없습니다.
따라서 입력된 텍스트를 토큰으로 분할하고 이를 숫자로 표현되는 벡터 형식으로 변환해야 합니다.
토큰화하는 방식에는 여러가지가 있으며, 이것이 토크나이저(Tokenizer)가 하는 역할입니다.
<AI, 이것만 알면 됩니다 ④ - 효율성> 중에서

Open AI에서 제공하는 도구를 이용해서 영어와 한국어 문장의 토큰을 확인해 본 결과, 한국어는 문자의 수가 적음에도 불구하고 토큰의 개수는 5배 더 많이 듭니다. ⁽¹⁾
왜 이러는 걸까요?
이는 영어와 한국어가 가진 언어적인 차이에 기인합니다.
‘이것(This)’이라는 단어를 기준으로 설명해보겠습니다.
- 단어를 구성하는 방식의 차이
한국어는 자음과 모음의 결합으로 글자를 만듭니다. ’이’는 ‘ㅇ(이응) + ㅣ(이)’가 합쳐진 형태로, 한 음절을 만들 때 최소 1개에서 최대 4개의 자음과 모음이 필요합니다. 반면 영어는 ‘this’처럼 알파벳의 나열로 구성됩니다. - 띄어쓰기의 차이
영어에서는 일반적으로 단어 앞뒤에 있는 공백 문자로 구분됩니다.⁽²⁾ ‘this’라는 단어 앞뒤로 공백이 있는 것입니다. 하지만 ‘이것’을 붙여 쓴 것처럼 한국어에는 단어 사이에 분리자가 없는 경우가 많습니다.
위의 2가지 차이를 바탕으로 보면 띄어쓰기를 기준으로 토큰화하기 쉬운 영어와 달리,
한국어의 토큰화는 훨씬 복잡합니다.
따라서 비슷한 문자 수이지만, 토큰 수가 크게 차이 나게 된 것입니다.
띄어쓰기를 기준으로 토큰화하기 쉬운 영어와 달리,
한국어의 토큰화는 훨씬 복잡합니다.
세 번째 이유: 단어 벡터맵의 빈약함
쪼개진 토큰은 다시 컴퓨터가 이해할 수 있는 기계어의 일종인 벡터로 변환됩니다.
잠깐, 왜 ‘벡터화’라는 표현을 쓸까요?
벡터라는 말이 어렵지만, 고등학교 때 힘(F)의 크기와 방향을 숫자로 표현할 때 배운 기억이 있을 겁니다.
그리고 방향이 다른 두 힘이 합쳐지면서 하나의 힘으로 다시 표현하기도 하고요.
여기서 중요한 건, 벡터 A와 B와 C는 관계를 가지고 있다는 것입니다.
고등학교 때 크기와 방향을 가진 물리량 정도로 배웠던 벡터는 큰 의미로 ‘관계 속에서 하나의 구성 요소’ 정도로 정의할 수 있습니다.
즉, ‘토큰의 벡터화’는 토큰 간의 (통계적) 관계를 정하는 것입니다.
토큰의 벡터화는 토큰 간의 (통계적) 관계를 정하는 것입니다.
죄송합니다. 쉽게 말하겠습니다.
단어끼리 얼만큼 친하거나 비슷한지 표현한 단어의 지도(map)를 만드는 게 벡터화의 목표입니다.
개구리와 비슷하거나 친한 단어는 어떤 게 있을까요?
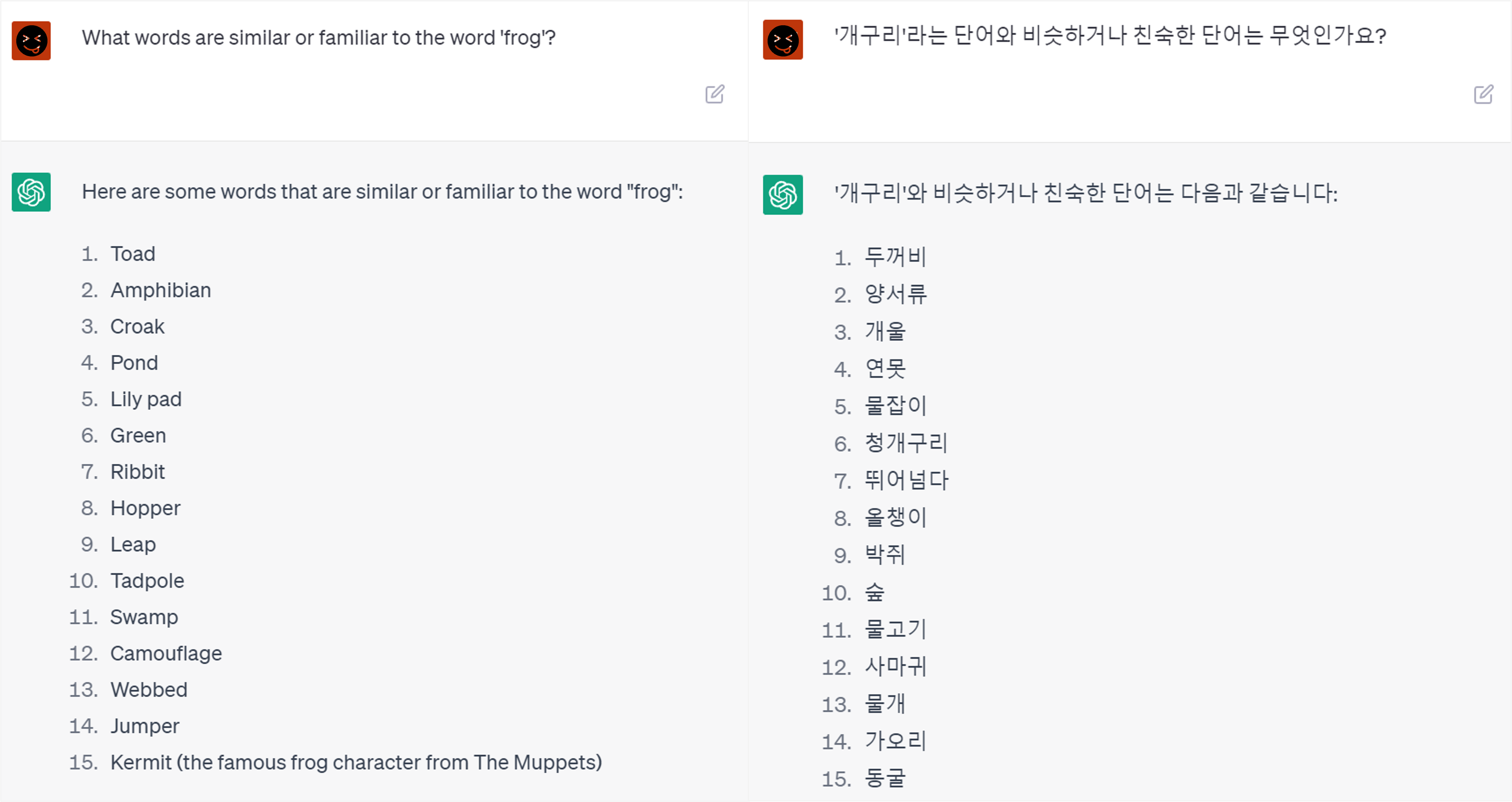
이런 단어 벡터맵을 통해 AI 모델은 주어진 질문을 이해하고 답변을 생성합니다.
즉, 입력된 텍스트에서 파생되는 단어들 중 답변에 활용할 단어를 고른다고 보면 됩니다.

카카오브레인에서 만든 KoGPT 모델은 온도(Temperature)의 값을 이용해 단어 벡터맵 중 답변에 활용할 범위를 조절할 수 있습니다.⁽⁴⁾
이러한 단어 벡터맵은 Word2Vec라는 기계학습을 통해 만들어집니다.
LLM 모델이 Word2Vec를 사용하는 것이 아닌, 사전 학습된 Transformer 모델을 사용합니다.
Transformer 모델이 사용하는 사전 데이터는 Word2Vec과 유사한 방식으로 구축된 데이터입니다.
하지만 아직 한국어 데이터에 대한 충분한 크기의 단어 벡터맵이 부재합니다.
그래서 위의 개구리와 비슷하거나 친숙한 단어에 대한 GPT의 각 언어의 답변을 비교해보면, 영어로 된 답변이 촘촘하고 풍부합니다. 한국어 답변에는 생뚱맞은 단어도 보입니다.
이는 첫 번째 이유였던 학습 데이터의 부족에서 파생된 문제로도 볼 수 있습니다.
개구리와 비슷하거나 친숙한 단어에 대한 GPT의 각 언어의 답변을 비교해보면,
영어로 된 답변이 촘촘하고 풍부합니다.
한국어 답변에는 생뚱맞은 단어도 보입니다.
그 외: 한국어 NER 등
비슷한 문제로는 ‘한국어 NER 데이터의 부족함’이 있습니다.
NER이란 Named Entity Recognition의 약자로 회사 이름, 지역 이름, 인물 이름 등과 같은 고유명사를 인식하는 것이며, 자연어 처리(NLP)에서 중요한 전처리 과정 중 하나입니다.

예를 들면, Apple은 사과이기도 하지만, 한 기업의 이름이기도 합니다.
Apple이 들어간 문장을 모두 ‘사과’로만 인식한다면, 모델의 성능은 떨어질 수 밖에 없습니다.
한국어 NER 데이터는 매우 부족한 상황이며⁽⁵⁾, 이와 같은 기초 작업이 부진한 상태에서 한국어 특화 AI 모델을 만든다면 모래 위의 성과 같은 일입니다.
이 외에도 높임말이나 주어나 목적어가 생략되는 등의 복잡하고 정교한 언어 구조도 한국어 LLM이 만만치 않은 이유 중의 하나입니다.
한국어 GPT가 마주한 과제
한국어 GPT가 어려운 이유 3가지를 살펴봤습니다.
위의 3가지 이유를 달리 말하면 한국어 GPT가 해결해야 할 과제입니다.
- 양질의 한국어 학습데이터 확보
- 한국어에 특화된 토크나이저(Tokenizer) 개발
- 단어 벡터맵, NER 등 기초 데이터 생성
결코 쉽지 않은 일을 피하지 않고 정면으로 맞서 싸우는 것을 ‘도전’이라고 합니다.
'한국어 특화 AI 모델'이라는 도전을 하고 있는 국내 기업들이 반드시 유의미한 성과를 만들어내길 응원합니다.
Reference
(1) Open AI: https://platform.openai.com/tokenizer
(2) Oracle: https://docs.oracle.com/cd/E26925_01/html/E27145/glmag.html
(3) Stanford Univ.: https://nlp.stanford.edu/projects/glove/
(4) 카카오브레인: https://developers.kakao.com/docs/latest/ko/kogpt/common
(5) 트위그팜 LETR: https://www.letr.ai/blog/tech-20210723
'AI • 빅데이터 인사이트' 카테고리의 다른 글
| AI, 이것만 알면 됩니다 ④ - 효율성 (0) | 2023.04.15 |
|---|---|
| AI, 이것만 알면 됩니다 ③ - 오픈소스 AI (1) | 2023.04.08 |
| AI, 이것만 알면 됩니다 ② - 코파일럿 2편 (1) | 2023.04.02 |
| AI, 이것만 알면 됩니다 ② - 코파일럿 (1) | 2023.04.02 |
| AI, 이것만 알면 됩니다 ① - 프롬프트 (2) | 2023.03.27 |