2023. 3. 14. 22:26ㆍ연구 동향
파비 AI 대학원에서는 뭘 배울까 - 주가수익률 예측 인공지능(?)
2021년 가을부터 SIAI에서 MBA in AI & BigData 과정을 이수 중인 재학생으로, 논문 발표와 졸업을 앞두고(? 제발...!) 있다.
마음 한 구석에 항상 '대학원에 관한 글을 써야지'라는 생각이 있었는데 이제서야 쓰게 됐다.

대학원 입학 계기, 학생들 분위기, 공부량 등 여러가지 소재가 있겠지만,
첫 글은 파비의 '인공지능' 대학원에서 도대체 어떤 걸 배우는지에 대해서 하나의 수업을 예로 들어 말해보고자 한다.
생각보다 '핫'한 주가수익률 예측 AI 모델
모 IT 대기업 인턴인 친구로부터 회사에서 사이드 프로젝트로 '주가수익률을 예측하는 AI 모델'을 만들려다가 실패했다는 말을 들은 적이 있다. 대학원 수업에서도 비슷한 주제를 다뤘기 때문에 내심 DS 분야에선 핫한 주제구나 싶었다.
그렇다면 파비 인공지능 대학원에서도 주가수익률 예측 AI 모델을 만드는 건가?
하는 궁금증이 들겠지만 답은 '아니오'다.
(어그로성 제목임은 인정한다...)
다만,
"주가수익률 예측 AI 모델을 만든다/만들었다는 이야기가 왜 (상당 부분) 헛소리일까"에 대한 논리적 근거를 배운다.
배우는 형식 또한 일반적인 강의 방식 대신, 기본 강의 이후 응용된 문제에 대한 팀발표로 진행되므로 팀원들과 함께 머리를 싸매고 답을 찾아낸다.
아래 부터는 발표 자료의 극초반인 'Data understanding' 부분을 조금 소개해보고자 한다.

주가수익률의 분포가 정규분포라면?
가장 먼저 1950년부터 현재까지의 주가수익률의 분포를 살펴봤을 때, 정규분포에 가깝지만 꼬리 부분이 두껍고, 한 쪽으로 치우쳐 있다. 이는 정규분포라는 가정에 비해 극단적인 사건이 실제로는 더 자주 발생한다는 것을 의미한다.
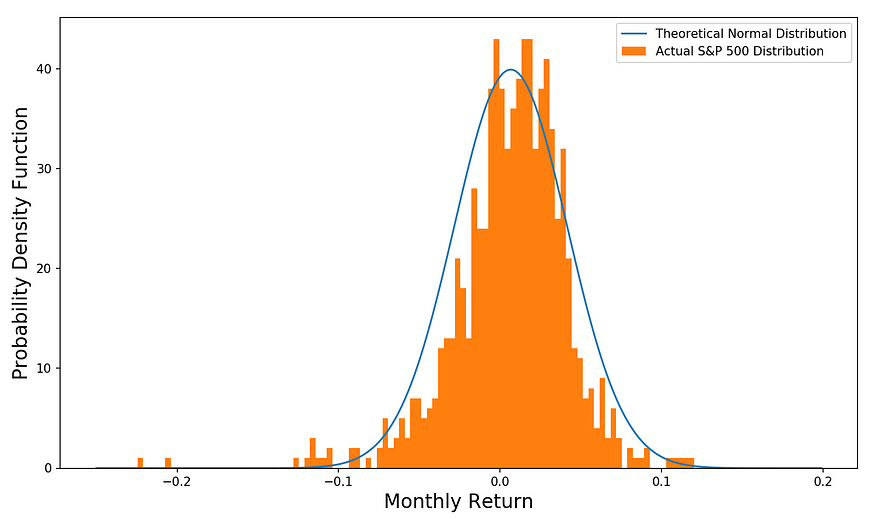
만약 주가수익률의 분포가 정규분포라면, 주가수익률을 예측하는 모든 모델은 전부 '꽝'이 될 것이다.
주사위 던지기 또는 동전 던지기 같이 정규분포를 따르는 다른 예시들과 같이 주가수익률 또한 우연의 산물일 뿐이라는 말 밖에 안 되기 때문이다.
- 우리는 왜 주식 시장을 예측할 수 없을까?: https://pdsi.pabii.com/can-data-science-accurately-predict-the-stock-market/
[해외DS] 데이터 사이언스가 주식 시장을 정확하게 예측할 수 있을까요? – 파비 데이터 사이언스
보다 ‘진보한’ 데이터 사이언스로 주식 시장을 더 높은 수준에서 더 정확하게 예측할 수 있을까요? The Science Times는 뭐라고 했을까요? 뭐가 됐든, 데이터 사이언스는 주식 시장에서 굉장히 중
pdsi.pabii.com
따라서 투자자들에게 수익을 안겨주거나 위험을 피하도록 돕는 게 Robo advisor의 목적이라면, 주가수익률 데이터 중 정규분포를 벗어나는 구간에서 작동해야지만 의미있는 예측 모델이 탄생한다.
(혹은 정규성을 띄는 데이터 특성을 발라내고 남은 부분에 대해서 설명하는 모델이거나)
즉 '우리가 만든 예측 모델은 조건부 주가수익률에 대해 설명하는 모델이다'라는 말이 없다면 AI로 했든 머신러닝을 했든 헛소리가 된다.
그렇다면 어떻게 정규분포를 벗어나는 데이터를 다룰 수 있을까?
사실 정규분포를 벗어난 데이터를 다루려면 선택지가 줄어든다. 정규분포는 1차 모멘트(평균)와 2차 모멘트(분산)의 특성만을 가지고 있는 분포이기 때문이다.
예를 들어, 회귀모델을 만들고 OLS을 쓴다면 데이터의 1차 모멘트(Coefficient)과 2차 모멘트(Standard deviation)만을 고려하게 된다. 따라서 위에 말한대로 주가수익률이 가진 정규분포보다 '꼬리가 더 두껍고'(4차 모멘트, kurtosis) '한 쪽으로 치우친'(3차 모멘트, skewness) 특성은 찾아내지 못한다.
이 부분이 "쓸모있는" Robo advisor가 되는데 훨씬 더 중요한 부분임에도 불구하고 말이다.
PCA도 위의 2가지의 이유로 적용하기 어렵다면 어떤 모델을 써야 할까?
혹은 어떤 데이터 전처리가 필요할까?
이런 고민에서부터 해당 주제의 Q1이 시작된다.
AI가 노벨경제학상을 탈 수 있을까?
수업의 마지막 질문은 "Factor Machine이 사람을 대체해서 의미있는 변수를 찾아낼 수 있을까?"로, 이에 대한 답은 파비 블로그에 있는 글로 대신한다.
- AI가 노벨경제학상을 탈 수 있을까? - 반박: https://blog.pabii.co.kr/ai-maniac-robo-advisor-disgrace/
[기획] AI가 노벨경제학상을 탈 수 있을까? - 반박 – 파비 데이터 사이언스 연구소
회사 가치가 거의 2천억에 육박하는 국내의 로보 어드바이저 회사가 하나 있다. 글 쓰는 시점 2시간 전에 그 회사 CEO가 현재 특허 진행 중이라는 회사의 핵심 알고리즘 하나를 브런치 글로 공개
pdsi.pabii.com
- AI가 노벨경제학상을 탈 수 있을까? - 반박 - 재반박: https://blog.pabii.co.kr/ai-maniac-robo-advisor-disgrace-followup/
[기획] AI가 노벨경제학상을 탈 수 있을까? - 반박 - 재반박 – 파비 데이터 사이언스 연구소
그나저나 이렇게 모르면서 바득바득 우기는 사람들은 왜 항상 공대 출신이지?왜 저렇게 우기는 공대생들은 Github 코드랑 예제만 보고 통계학 지식을 쌓을 생각을 안 할까??교육과정에서 수학, 통
pdsi.pabii.com
- AI가 노벨경제학상을 탈 수 있을까? - 반박 - 재반박 - 대학생 감상문: https://pdsi.pabii.com/ai-maniac-robo-advisor-disgrace-followup-student-review/
[기획] AI가 노벨경제학상을 탈 수 있을까? - 반박 - 재반박 - 대학생 감상문 – 파비 데이터 사이
정리하면, 그 로보 어드바이저 회사에서 귀납적으로 Factor를 찾아내겠다고 주장하려면, 우리 눈에 보이는 데이터 레벨이 아니라, 데이터의 실제 Vector Space (또는 Information Set 레벨에서의 Vector Space
pdsi.pabii.com
핵심적인 부분만 요약해보자면,
- Factor machine은 인공지능은 절대 아닐 뿐더러, 무식하게 가장 높은 설명력을 갖는 변수 조합을 찾아내는 Stepwise regression의 머신러닝 버전에 지나지 않는다.
- 변수를 찾아냈어도 인과관계(Causality)는 없고 단순한 상관관계(Correlation)만 높은 유효하지 않은 변수다.
- 특정 구간 또는 차원에서의 조건부 주가수익률에 대한 분석이 아닌 점에서, 랜덤 데이터를 설명하려고 하는 무가치한 모델이다.
이렇게 열심히 발표자료를 만들어 발표를 하면, 다른 팀에선 우리 팀 발표에 대한 피 튀기는 반박을 준비한다.
한 과목 내에 이 주제를 포함한 3개의 주제가 있고 각 주제에 대해 발표와 반박으로 구성된다.
모든 학기와 수업이 이런 형식은 아니고, 이전 학기에선 강의 형태로 기초적인 수학과 통계학 지식을 쌓는다. 이 후에는 머신러닝과 딥러닝, 강화학습 등의 수업으로 이어진다.
이 수업을 예시로 들어 글을 쓴 이유는, 이러한 사고 훈련이 졸업 논문을 쓸 때 큰 도움이 됐기 때문이다.
무작정 잘 들어맞는 변수를 찾아내기 위해 컴퓨팅 노가다를 하는 대신,
적절한 도메인 지식을 이용해서 합리적인 가설을 세우고 이를 모델로 만들어 검증하는 과정을 논문을 통해 경험해보면서 근 1년 간 SIAI에서 공부한 보람을 느꼈다.
데이터 특성은 어떠하지? → 전처리를 (어떻게) 해야 할까? → 어떤 방식으로 접근해야 할까? → 이런 문제가 있는데 우회/해결할 수 있는 방법이 있을까? → ... → 결과를 어떻게 해석해야 할까? → ...
비전공 공대생 무지랭이에서 DS 관련 분야 기사들을 이해하고 내 식대로 설명할 수 있을 만큼 성장하는 데엔, 이런 사고 훈련의 덕이 컸다. 또한, 논문을 읽을 때 비판적인 시각에서 한 마디라도 할 수 있게 된 것도 큰 수확이라고 생각한다.
파비 대학원 관련해서 궁금한 사람들을 위해 시간나는 대로 글을 써볼테니 궁금한 부분은 댓글로 남겨주세요^^!
'연구 동향' 카테고리의 다른 글
| 랜덤 포레스트(Random Forest)에서 다중공선성(Multi-collinearity) 탐색하기 (1) | 2024.02.26 |
|---|---|
| 부동산경매시장에서 매각가격은 할인되는가?(진남영 외 2인, 2010) (0) | 2022.12.21 |
| 물류센터 투자측면에서 입지선정 및 임대료 결정에 영향을 미치는 요인에 관한 연구(이남승, 2020) (1) | 2022.12.11 |
| 딥러닝을 이용한 주택 경매시장 예측에 관한 연구(2020, 김선아 및 전해정) (1) | 2022.12.10 |
| 부동산 뉴스와 아파트 매매가격과 거래량 간의 관계에 대한 빅데이터 시계열 분석(2020, 전해정) (1) | 2022.12.07 |